 Home-theater-designers
Home-theater-designers
தரவு ஆய்வாளராக, பல தரவுத்தொகுப்புகளை இணைக்க வேண்டிய அவசியத்தை நீங்கள் அடிக்கடி எதிர்கொள்வீர்கள். உங்கள் பகுப்பாய்வை முடிக்கவும், உங்கள் வணிகம்/பங்குதாரர்களுக்கு ஒரு முடிவுக்கு வரவும் இதைச் செய்ய வேண்டும்.
வெவ்வேறு அட்டவணைகளில் சேமிக்கப்படும் போது தரவைப் பிரதிநிதித்துவப்படுத்துவது பெரும்பாலும் சவாலானது. இதுபோன்ற சூழ்நிலைகளில், நீங்கள் எந்த நிரலாக்க மொழியில் வேலை செய்கிறீர்கள் என்பதைப் பொருட்படுத்தாமல், சேருபவர்கள் தங்கள் தகுதியை நிரூபிக்கிறார்கள்.
அன்றைய வீடியோவை உருவாக்கவும்
Python இணைப்புகள் SQL இணைப்புகள் போன்றவை: அவை பொதுவான குறியீட்டில் அவற்றின் வரிசைகளைப் பொருத்துவதன் மூலம் தரவுத் தொகுப்புகளை இணைக்கின்றன.
குறிப்புக்காக இரண்டு டேட்டா ஃப்ரேம்களை உருவாக்கவும்
இந்த வழிகாட்டியில் உள்ள உதாரணங்களைப் பின்பற்ற, நீங்கள் இரண்டு மாதிரி டேட்டாஃப்ரேம்களை உருவாக்கலாம். ஐடி, முதல் பெயர் மற்றும் கடைசி பெயர் ஆகியவற்றைக் கொண்ட முதல் டேட்டாஃப்ரேமை உருவாக்க பின்வரும் குறியீட்டைப் பயன்படுத்தவும்.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)முதல் படி, இறக்குமதி பாண்டாக்கள் நூலகம். நீங்கள் ஒரு மாறியைப் பயன்படுத்தலாம், அ , DataFrame கன்ஸ்ட்ரக்டரில் இருந்து முடிவைச் சேமிக்க. உங்களுக்குத் தேவையான மதிப்புகளைக் கொண்ட அகராதியை கட்டமைப்பாளருக்கு அனுப்பவும்.
2019 புதுப்பித்தலுக்குப் பிறகு விண்டோஸ் 10 மெதுவாக உள்ளது
இறுதியாக, நீங்கள் எதிர்பார்ப்பது போல் அனைத்தையும் சரிபார்க்க, அச்சு செயல்பாட்டுடன் DataFrame மதிப்பின் உள்ளடக்கங்களைக் காண்பிக்கவும்.
இதேபோல், நீங்கள் மற்றொரு DataFrame ஐ உருவாக்கலாம், பி , இதில் ஐடி மற்றும் சம்பள மதிப்புகள் உள்ளன.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)நீங்கள் ஒரு கன்சோல் அல்லது ஒரு IDE இல் வெளியீட்டைச் சரிபார்க்கலாம். இது உங்கள் DataFrames இன் உள்ளடக்கங்களை உறுதிப்படுத்த வேண்டும்:
பைத்தானில் உள்ள மெர்ஜ் செயல்பாட்டிலிருந்து இணைதல் எவ்வாறு வேறுபடுகிறது?
டேட்டாஃப்ரேம்களைக் கையாள நீங்கள் பயன்படுத்தக்கூடிய முக்கிய நூலகங்களில் பாண்டாஸ் நூலகம் ஒன்றாகும். டேட்டாஃப்ரேம்கள் பல தரவுத் தொகுப்புகளைக் கொண்டிருப்பதால், அவற்றுடன் இணைவதற்கு பைத்தானில் பல்வேறு செயல்பாடுகள் உள்ளன.
DataFrames ஐ இணைக்க நீங்கள் பயன்படுத்தக்கூடிய பலவற்றுடன் இணைதல் மற்றும் ஒன்றிணைத்தல் செயல்பாடுகளை பைதான் வழங்குகிறது. இந்த இரண்டு செயல்பாடுகளுக்கும் இடையே ஒரு தெளிவான வேறுபாடு உள்ளது, அதைப் பயன்படுத்துவதற்கு முன்பு நீங்கள் நினைவில் கொள்ள வேண்டும்.
இணைப்பு செயல்பாடு இரண்டு டேட்டாஃப்ரேம்களை அவற்றின் குறியீட்டு மதிப்புகளின் அடிப்படையில் இணைக்கிறது. தி merge செயல்பாடு DataFrames ஐ ஒருங்கிணைக்கிறது குறியீட்டு மதிப்புகள் மற்றும் நெடுவரிசைகளின் அடிப்படையில்.
பைத்தானில் சேர்வதைப் பற்றி நீங்கள் தெரிந்து கொள்ள வேண்டியது என்ன?
கிடைக்கக்கூடிய சேர்க்கைகளின் வகைகளைப் பற்றி விவாதிப்பதற்கு முன், இங்கே கவனிக்க வேண்டிய சில முக்கியமான விஷயங்கள்:
- SQL இணைப்புகள் மிகவும் அடிப்படையான செயல்பாடுகளில் ஒன்றாகும் மற்றும் பைத்தானின் இணைப்பிற்கு மிகவும் ஒத்திருக்கிறது.
- DataFrames இல் சேர, நீங்கள் இதைப் பயன்படுத்தலாம் pandas.DataFrame.join() முறை.
- இயல்புநிலை இணைப்பானது இடது இணைப்பைச் செய்கிறது, அதேசமயம் ஒன்றிணைப்பு செயல்பாடு உள் இணைப்பைச் செய்கிறது.
பைதான் இணைப்பிற்கான இயல்புநிலை தொடரியல் பின்வருமாறு:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)முதல் டேட்டா ஃபிரேமில் சேரும் முறையை செயல்படுத்தி, இரண்டாவது டேட்டா ஃப்ரேமை அதன் முதல் அளவுருவாக அனுப்பவும். மற்றவை . மீதமுள்ள வாதங்கள்:
- அன்று , ஒன்றுக்கு மேற்பட்டவை இருந்தால், அதில் சேர்வதற்கான குறியீட்டை பெயரிடுகிறது.
- எப்படி , எந்த உள், வெளி, இடது மற்றும் வலது உட்பட, சேரும் வகையை வரையறுக்கிறது.
- பின்னொட்டு , எந்த உங்கள் நெடுவரிசைப் பெயரின் இடது பின்னொட்டு சரத்தை வரையறுக்கிறது.
- பின்னொட்டு , எந்த உங்கள் நெடுவரிசைப் பெயரின் வலது பின்னொட்டு சரத்தை வரையறுக்கிறது.
- வகைபடுத்து , எந்த இதன் விளைவாக வரும் DataFrame ஐ வரிசைப்படுத்த வேண்டுமா என்பதைக் குறிக்கும் பூலியன்.
பைத்தானில் பல்வேறு வகையான இணைப்புகளைப் பயன்படுத்த கற்றுக்கொள்ளுங்கள்
பைத்தானில் சில சேர விருப்பங்கள் உள்ளன, அவை நேரத்தின் தேவையைப் பொறுத்து நீங்கள் உடற்பயிற்சி செய்யலாம். இணைக்கும் வகைகள் இங்கே:
1. இடது சேரவும்
இடது இணைப்பானது முதல் டேட்டாஃப்ரேமின் மதிப்புகளை அப்படியே வைத்திருக்கும் அதே வேளையில் இரண்டாவது ஒன்றிலிருந்து பொருந்தும் மதிப்புகளைக் கொண்டுவருகிறது. எடுத்துக்காட்டாக, நீங்கள் பொருந்தக்கூடிய மதிப்புகளைக் கொண்டு வர விரும்பினால் பி , நீங்கள் அதை பின்வருமாறு வரையறுக்கலாம்:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)வினவல் இயங்கும் போது, வெளியீட்டில் பின்வரும் நெடுவரிசை குறிப்புகள் இருக்கும்:
- ID_இடது
- பெயர்
- பெயர்
- ஐடி_வலது
- சம்பளம்
இந்த இணைப்பானது முதல் DataFrame இலிருந்து முதல் மூன்று நெடுவரிசைகளையும், இரண்டாவது DataFrame இலிருந்து கடைசி இரண்டு நெடுவரிசைகளையும் இழுக்கிறது. இது பயன்படுத்தியுள்ளது பின்னொட்டு மற்றும் பின்னொட்டு இரண்டு தரவுத்தொகுப்புகளிலிருந்தும் ஐடி நெடுவரிசைகளை மறுபெயரிடுவதற்கான மதிப்புகள், இதன் விளைவாக வரும் புலப் பெயர்கள் தனித்துவமானவை என்பதை உறுதிப்படுத்துகிறது.
வெளியீடு பின்வருமாறு:

2. வலது சேரவும்
முதல் டேபிளில் இருந்து பொருந்தக்கூடிய மதிப்புகளைக் கொண்டுவரும் போது, வலது இணைப்பானது இரண்டாவது டேட்டாஃப்ரேமின் மதிப்புகளை அப்படியே வைத்திருக்கும். எடுத்துக்காட்டாக, நீங்கள் பொருந்தக்கூடிய மதிப்புகளைக் கொண்டு வர விரும்பினால் அ , நீங்கள் அதை பின்வருமாறு வரையறுக்கலாம்:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)வெளியீடு பின்வருமாறு:
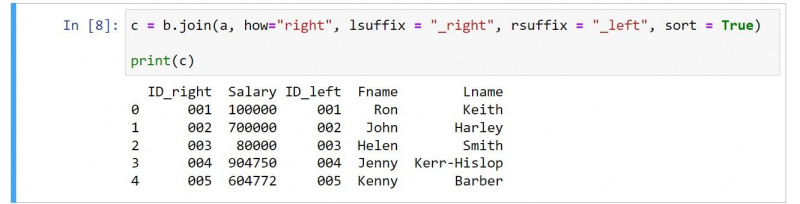
நீங்கள் குறியீட்டை மதிப்பாய்வு செய்தால், சில தெளிவான மாற்றங்கள் உள்ளன. எடுத்துக்காட்டாக, முடிவு முதல் DataFrame இன் நெடுவரிசைகளுக்கு முன் இரண்டாவது DataFrame இன் நெடுவரிசைகளை உள்ளடக்கியது.
ஆன்லைனில் இலவச திரைப்படங்கள் பதிவு இல்லை
நீங்கள் மதிப்பைப் பயன்படுத்த வேண்டும் சரி அதற்காக எப்படி சரியான இணைப்பைக் குறிப்பிடுவதற்கான வாதம். மேலும், நீங்கள் எப்படி மாற்றலாம் என்பதைக் கவனியுங்கள் பின்னொட்டு மற்றும் பின்னொட்டு சரியான இணைப்பின் தன்மையை பிரதிபலிக்கும் மதிப்புகள்.
உங்கள் வழக்கமான இணைப்பில், வலதுபுற இணைப்போடு ஒப்பிடும்போது, இடது, உள் மற்றும் வெளிப்புற இணைப்புகளை அடிக்கடி பயன்படுத்துவதை நீங்கள் காணலாம். இருப்பினும், பயன்பாடு முற்றிலும் உங்கள் தரவுத் தேவைகளைப் பொறுத்தது.
3. உள் இணைப்பு
ஒரு உள் இணைப்பு இரண்டு டேட்டாஃப்ரேம்களிலிருந்தும் பொருந்தும் உள்ளீடுகளை வழங்குகிறது. இணைப்புகள் வரிசைகளைப் பொருத்த குறியீட்டு எண்களைப் பயன்படுத்துவதால், உள் இணைப்பானது பொருந்தக்கூடிய வரிசைகளை மட்டுமே வழங்கும். இந்த விளக்கத்திற்கு, பின்வரும் இரண்டு DataFrames ஐப் பயன்படுத்துவோம்:
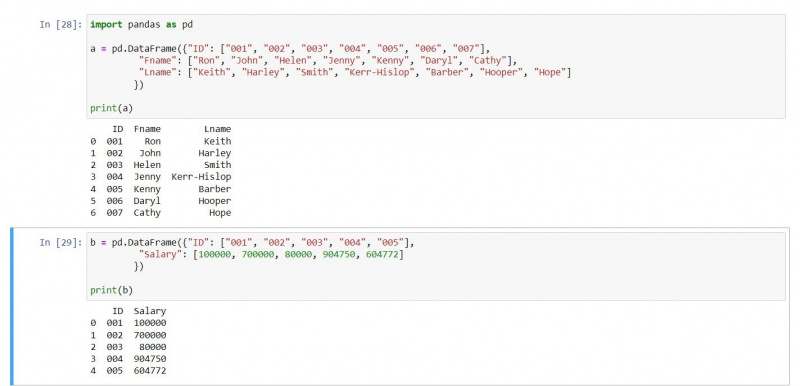
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)வெளியீடு பின்வருமாறு:
நீங்கள் ஒரு உள் இணைப்பைப் பயன்படுத்தலாம், பின்வருமாறு:
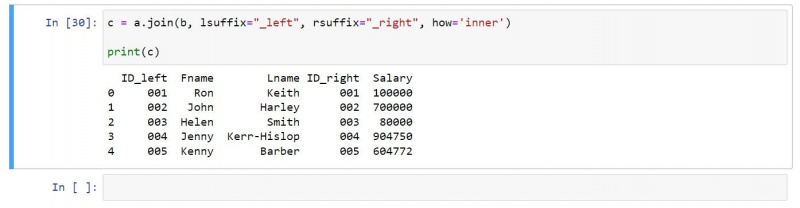
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)இதன் விளைவாக வரும் வெளியீடு இரண்டு உள்ளீட்டு DataFrames இல் இருக்கும் வரிசைகளை மட்டுமே கொண்டுள்ளது:
4. வெளிப்புற இணைப்பு
ஒரு வெளிப்புற இணைப்பு இரண்டு DataFrames இலிருந்தும் அனைத்து மதிப்புகளையும் வழங்குகிறது. பொருந்தக்கூடிய மதிப்புகள் இல்லாத வரிசைகளுக்கு, இது தனிப்பட்ட கலங்களில் பூஜ்ய மதிப்பை உருவாக்குகிறது.
மேலே உள்ள அதே DataFrame ஐப் பயன்படுத்தி, வெளிப்புற இணைப்பிற்கான குறியீடு இதோ:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)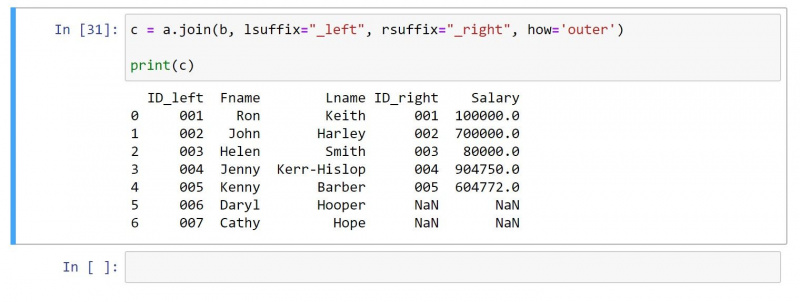
பைத்தானில் இணைவதைப் பயன்படுத்துதல்
இணைத்தல், அவற்றின் இணை செயல்பாடுகள், ஒன்றிணைத்தல் மற்றும் இணைத்தல் போன்றவை, ஒரு எளிய சேரும் செயல்பாட்டை விட அதிகமான வழிகளை வழங்குகின்றன. அதன் தொடர்ச்சியான விருப்பங்கள் மற்றும் செயல்பாடுகளைக் கருத்தில் கொண்டு, உங்கள் தேவைகளைப் பூர்த்தி செய்யும் விருப்பங்களை நீங்கள் தேர்வு செய்யலாம்.
பைதான் வழங்கும் நெகிழ்வான விருப்பங்கள் மூலம், சேரும் செயல்பாட்டுடன் அல்லது இல்லாமலேயே நீங்கள் பெறப்பட்ட தரவுத்தொகுப்புகளை ஒப்பீட்டளவில் எளிதாக வரிசைப்படுத்தலாம்.